背景
微店任务调度中心(TOC)每天承担千万甚至亿量级的任务调度,不单单是循环的传统任务调度,还承担了类似于延时消息的一次性调度。但是目前设计上仍然比较原始,是TOC抢分布式锁后通过线程不断扫表读取需要调度的job,再通过 dubbo 调度job,形成了一人工作,他人围观的场景。虽然能满足目前的需求,但是已经越来越力不从心,在一些极端的情况下,比如某个应用注册任务激增的情况下,就会出现大量的调度延迟。于是以能无限水平扩容为目标的调度方案的改造势在必行。
老架构设计
服务通过抢占zk分布式锁来获得执行权限,从数据库中扫表获得需要执行的任务。因为我们有256张分表,我们也限制成从每张分表里读取100条记录,每次最大总数也就是25600。
执行时通过 dubbo rpc 回调注册方来执行任务。
注册方执行完后会回调调度中心更新任务状态。
调研
调研时发现,目前开源的比较流行的调度中心主要有两种方案。一种是中心化的,例如xxl-job。另外一种是去中心化的,例如 elastic-job。
由于公司内部zookeeper的使用已经比较成熟了,而且对高可用的要求比较高。于是着重研究了es-job。
es-job实现分片的核心在于利用zk作为协调者来进行分片。
关键流程如下:
1、每一个服务启动时,向zk的worker节点注册,同时参与leader的选举。
2、leader选举成功后,在需要进行分片的任务执行时,获取worker节点的数量,对任务进行切分,分配至worker节点下。
3、worker节点执行任务时从cache读取需要执行的任务进行执行,同时更新任务执行的状态。
关键的流程是比较简单的,主要就是利用了zk。
新架构设计
我们公司的调度产品有个特点,底层数据库就是分表的,固定的256张表,那么存在天然的分片优势。
于是,我们在设计时也就比较简单,将256张表分给注册在zk worker节点下的worker就行。
实现
1、调度中心起来后,向zk 注册 worker临时节点,同时监听链接状态和节点 node cache 的变化。
2、每个实例都参与 leader 选举。成为leader 的实例 对 worker 根节点添加监听器,监听 worker 变化事件。
3、leader 根据 worker 数量,对 256 张表进行分配,分配结果写入到 node cache。
4、worker 监听到 node cache 发生变化,获取最新数据, 写入本地的缓存。
5、当 worker 与 zk 之间连接发生波动时,清空本地缓存。
6、调度扫描线程根据本地缓存里的表,进行扫表执行。
效果
老架构CPU监控
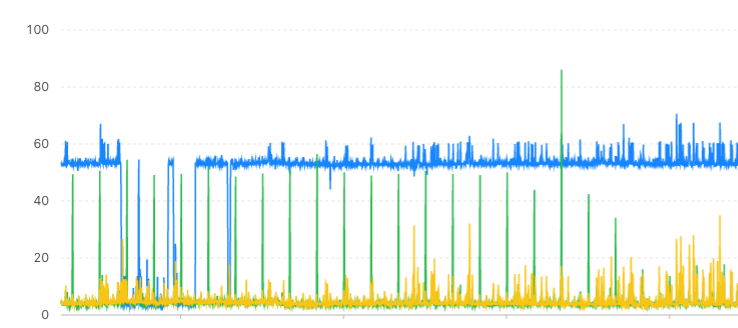
新架构CPU监控
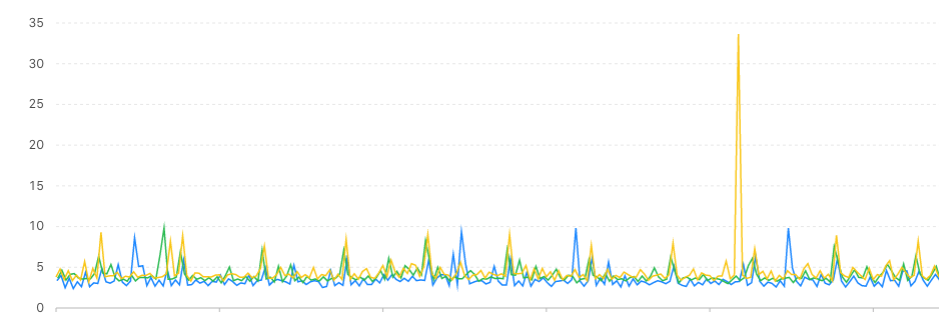
可以看到,一人干活,他人围观的场面一去不复返了。大家一起干活,很和谐。