一、现象
前段时间在做数据同步任务的切换,在切换到MR后,总共36个任务,10个变小,16个不变,10个变大,而且变大的体积基本上都是翻倍。另外公司的存储空间当时较为紧张,所以需要解决这个体积增大的问题。
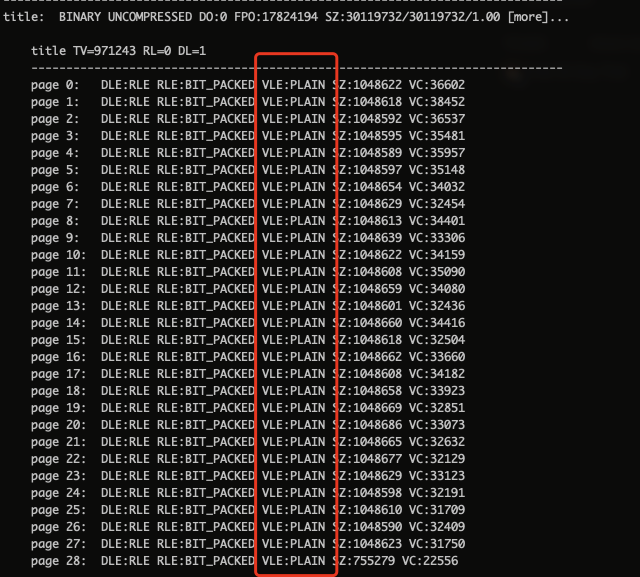
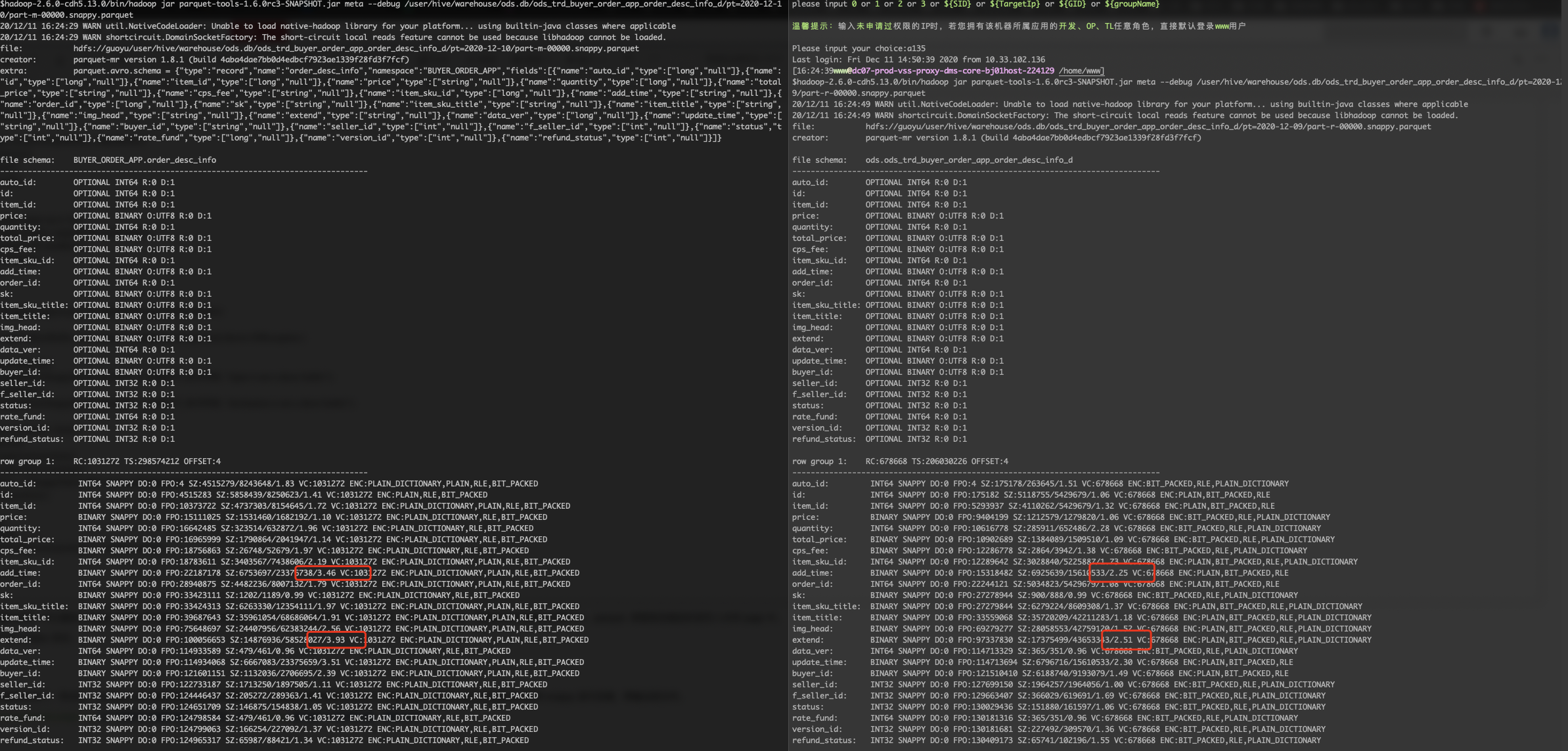
下图是用 parquet-tools 解析文件获得到,可以看到,左侧 outscan 比 右侧 mr 在好几个column上压缩率都高不少
ods_trd_buyer_order_app_order_desc_info_d
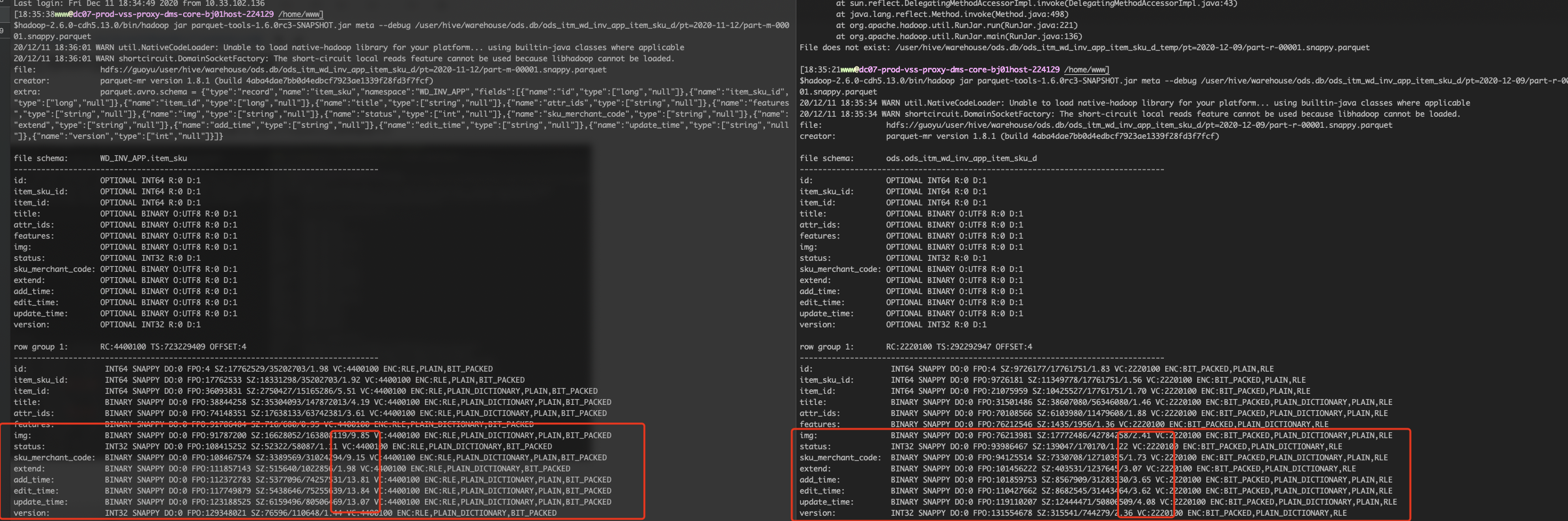
ods_itm_wd_inv_app_item_sku_d 则更加明显
二、研究
1、outscan(之前的同步方式,下面不再注释)和mr同步的区别。
| outscan | mr |
|---|---|
| 直接 map hfile,没有reduce过程 | 分别map text 增量和 parquet 全量,再进行reduce |
| 输出类为 AvroParquetOutputFormat | 输出类为 ParquetOutputFormat |
2、尝试调整 parquet 参数
先放一张 parquet 文件格式图
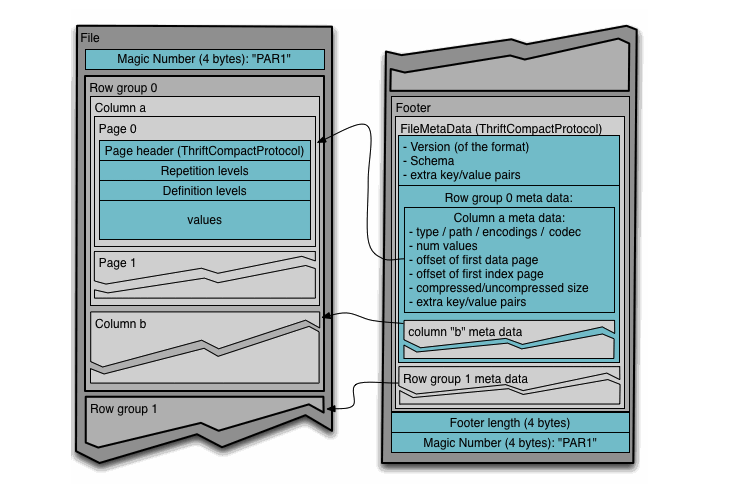
可以看到 parquet 文件我们最需要关心的部分为 RowGroup、Column、 Page 。
当我们写 parquet 文件时,先会构造 RowGroup,然后根据不同的列构造不同的 Column,再分别在 Column 中构造 Page,然后向 Page 中写入数据,在每次写入时,会由
accountForValueWritten() 判断是否需要 writePage ,如果需要的话会把当前 Column 中的 数据输出到一个 Collect,snappy 压缩也是在这个过程。当整个RowGroup到达整个 parquet.block.size 大小时,会把整个 RowGroup 输出到 hdfs。
| 尝试调整的参数 | 调整到的值 | 对体积大小的影响 |
|---|---|---|
| parquet.block.size | 1G | 基本无影响 |
parquet.page.size |
1-128M | 基本无影响 |
parquet.dictionary.page.size |
1-128M | 当只读 text 时,对体积约有20%的减小,在线上跑时,对体积基本无影响 |
io.compression.codec.snappy.buffersize |
1M | 基本无影响 |
io.file.buffer.size |
1M | 基本无影响 |
| 输出类改为 AvroParquet | 基本无影响 | |
| 升级 parquet 版本 | 基本无影响 | |
3、查看 outscan 和 mr 的日志区别
a) outscan
1 | Dec 11, 2020 4:08:22 PM INFO: org.apache.parquet.hadoop.codec.CodecConfig: Compression: SNAPPY |
b) mr
1 | Dec 11, 2020 12:09:45 AM INFO: org.apache.parquet.hadoop.codec.CodecConfig: Compression: SNAPPY |
可以看到 parquet.block.size 、page.size 、 dictionary.page.size 这些参数都一样的情况下,在一个 rowgroup 中 mr 能写入的数据少于 outscan 能写入的数据,这就是因为压缩率不同导致的。
3、查看源码
a) snappy
1 | org.apache.parquet.hadoop.CodecFactory.BytesCompressor#compress public BytesInput compress(BytesInput bytes) throws IOException { final BytesInput compressedBytes; if (codec == null) { compressedBytes = bytes; } else { compressedOutBuffer.reset(); if (compressor != null) { // null compressor for non-native gzip compressor.reset(); } CompressionOutputStream cos = codec.createOutputStream(compressedOutBuffer, compressor); bytes.writeAllTo(cos); cos.finish(); cos.close(); compressedBytes = BytesInput.from(compressedOutBuffer); } return compressedBytes; } org.apache.parquet.hadoop.codec.SnappyCompressor#compress @Override public synchronized int compress(byte[] buffer, int off, int len) throws IOException { SnappyUtil.validateBuffer(buffer, off, len); if (needsInput()) { // No buffered output bytes and no input to consume, need more input return 0; } if (!outputBuffer.hasRemaining()) { // There is uncompressed input, compress it now int maxOutputSize = Snappy.maxCompressedLength(inputBuffer.position()); if (maxOutputSize > outputBuffer.capacity()) { outputBuffer = ByteBuffer.allocateDirect(maxOutputSize); } // Reset the previous outputBuffer outputBuffer.clear(); inputBuffer.limit(inputBuffer.position()); inputBuffer.position(0); int size = Snappy.compress(inputBuffer, outputBuffer); outputBuffer.limit(size); inputBuffer.limit(0); inputBuffer.rewind(); } // Return compressed output up to 'len' int numBytes = Math.min(len, outputBuffer.remaining()); outputBuffer.get(buffer, off, numBytes); bytesWritten += numBytes; return numBytes; } org.xerial.snappy.Snappy#compress(java.nio.ByteBuffer, java.nio.ByteBuffer) public static int compress(ByteBuffer uncompressed, ByteBuffer compressed) throws IOException { if (!uncompressed.isDirect()) throw new SnappyError(SnappyErrorCode.NOT_A_DIRECT_BUFFER, "input is not a direct buffer"); if (!compressed.isDirect()) throw new SnappyError(SnappyErrorCode.NOT_A_DIRECT_BUFFER, "destination is not a direct buffer"); // input: uncompressed[pos(), limit()) // output: compressed int uPos = uncompressed.position(); int uLen = uncompressed.remaining(); int compressedSize = ((SnappyNativeAPI) impl).rawCompress(uncompressed, uPos, uLen, compressed, compressed.position()); // pos limit // [ ......BBBBBBB.........] compressed.limit(compressed.position() + compressedSize); return compressedSize; } |
上面是 snappy 压缩的过程,可以看到 snappy 对输入的流除了不能超过 Integer.MAXVALUE,其他没有做什么限制。也就是输入什么,它就按它的逻辑去压缩什么。parquet 获取到压缩后的流写入内存 page 中。
因此推测问题应该不在 snappy 这边。
b) parquet
parquet 源码我就不复制过来了,有点多。 parquet 也只是获取到 reduce 的输出流,对数据根据类型和内容进行不同的编码,然后形成它的数据结构再用 snappy 进行压缩,再输出到文件。
需要注意的是 parquet.dictionary.page.size 这个参数会对编码造成一定影响,当 dictionary 里的值大于配置的值,编码会退化。
c) mapreduce
重点怀疑是在 reduce 后或者过程中,输出数据之间较为稀疏,导致压缩效率不理想。但是这块不是非常熟悉,需要找方法验证。
三、结果
已经找到原因,确实是 reduce 后数据较为稀疏导致压缩率不高。
前天在排查的时候,发现 outscan 出来的数据某些 ID 都是连续的,而后面的 title 数据会有基本相同的数据排在一起。怀疑某些表的数据有特殊性,在 ID 连续时,其他列的数据基本相同。后续也证实了这个猜想。
当某些表的 xxx_id 连续分布在同一个 reduce 中时,会对压缩率有极大的提高,例如
| item_sku_id| title |
| 11231 | 黑色羊毛衫XL|
| 11232 | 黑色羊毛衫XXL|
| 11233 | 遥控汽车A |
| 11234 | 遥控汽车B |
默认的 partition 会将 11231,11233发送到 reduce A , 11232 ,11234 发送到 reduce B,最后产生两个内容基本没有重复的文件,会导致数据不连续 压缩率不理想。
而 outscan 没有 reduce 的过程,直接 map 完有序输出,不会将连续的 id 切分到各个 reduce。
解决办法
1 | public int getPartition(Text text, Text value, int numPartitions) { long key = Long.parseLong((text.toString().split("_"))[0]); return (int) (key/100%numPartitions); } |
增加了一个 partition,专门给这些数据上有连续性的表用,将连续的 ID 发送到同一个 reduce 输出。sub最后两位是观察我们DB里的数据的连续性得出的经验值。
四、解决问题之外的研究
最后研究下 parquet 的编码对 parquet 本身压缩率有多大的影响。
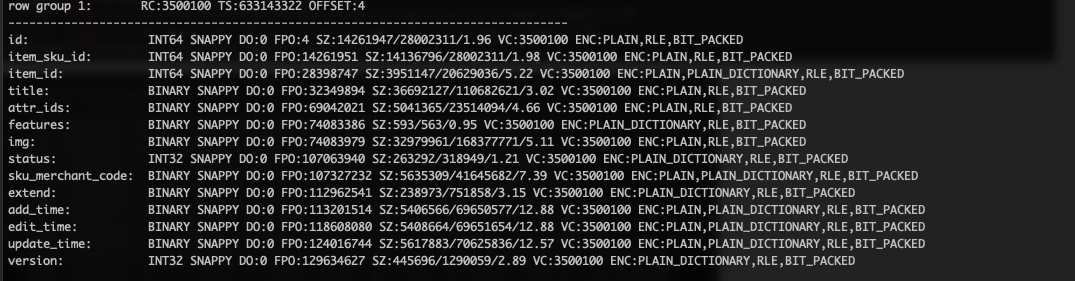
开启 SNAPPY 压缩,自定义分区方式重跑 ods_itm_wd_inv_app_item_sku_d 任务结果体积大小及编码结果

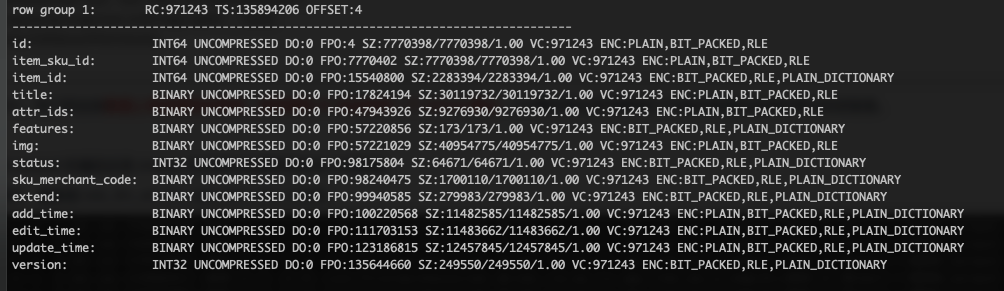
关闭SNAPPY压缩后,自定义分区方式重新跑 ods_itm_wd_inv_app_item_sku_d 任务结果体积大小及编码结果。

关闭SNAPPY压缩后,默认分区方式重新跑 ods_itm_wd_inv_app_item_sku_d 任务结果体积大小及编码结果。

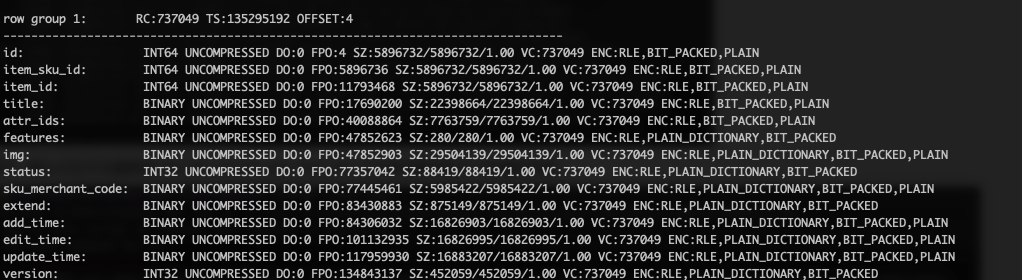
根据上面的数据可以得出,在数据密集的情况下,parquet 本身对数据的压缩率就会高一些,在数据不密集的情况下 5.1T ,数据密集的情况下 3.7T。
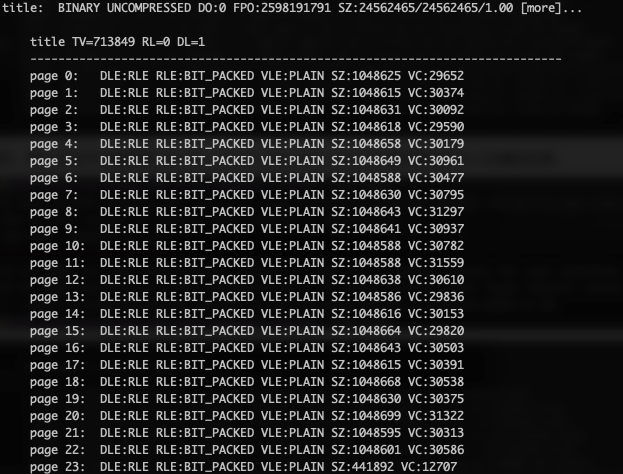
下面两张图可以看到,有序和无序对都是字符的 title 列的编码方式影响不大,都用PLAIN编码。